3 Corona- als Erstglied: Eine Produktivitätsanalyse
Als Beispiel sehen wir uns Komposita mit dem Erstglied Corona- an. Hier kann man zwar streiten, ob es sich um ein eigenes Wortbildungsmuster handelt oder ob wir es einfach mit Instanzen der allgemeineren N+N-Komposition zu tun haben, allerdings lässt sich durchaus argumentieren, dass Corona-Komposita in letzter Zeit so häufig geworden sind, dass man [Corona+X] als eigenständiges Kompositionsmuster annehmen kann. Dabei kann es nicht nur aus morphologischer, sondern auch aus sozio- und diskurslinguistischer Sicht interessant sein, einen Blick darauf zu werfen, mit welchen Bestimmungsgliedern sich das Erstglied Corona- verbindet.
Praktischerweise können wir über das Digitale Wörterbuch der Deutschen Sprache (DWDS) mittlerweile auf ein Corona-Korpus zugreifen (Barbaresi 2020), das nach einmaliger Registrierung zugänglich ist. Aufgrund der flexibleren Suchanfragemöglichkeiten verwenden wir das Tool Dstar (https://kaskade.dwds.de/dstar/), um das Korpus zu durchsuchen. (Eine gute Anleitung zu Dstar findet sich in diesem Tutorial von Andreas Blombach: http://sprachwissenschaft.fau.de/personen/daten/blombach/korpora.pdf)
Mit folgender Suchanfrage lasse ich mir alle Instanzen auszählen, bei denen auf die Buchstabenfolge Corona, ggf. gefolgt von einem Bindestrich, noch mindestens ein weiterer Buchstabe folgt: count( $w=/Corona-?.+/gi ) #by[$l]. (Das “gi” nach dem regulären Ausdruck ist eine Eigenheit der DWDS-Suchanfragesprache DDC: Mit g gebe ich an, dass ich genau das suche, also bspw. nichts, wo dem String Corona noch Anderes vorausgeht, und mit i gebe ich an, dass die Suche case-insensitive sein soll, also Groß- und Kleinschreibung ignoriert werden sollen).
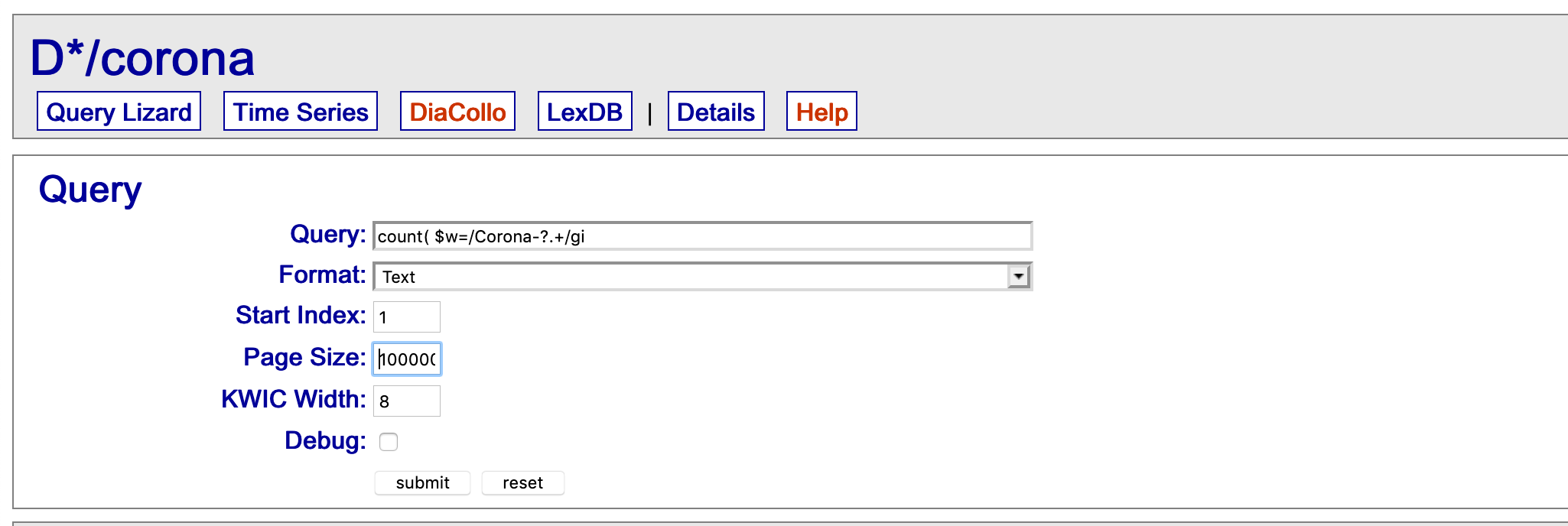
Fig. 3.1: Types und Tokens
Wie 3.1 zeigt, habe ich als Exportoption “Text” gewählt, sodass wir die Daten im Rohtextformat erhalten, und die Seitengröße (“Page size”) so weit erhöht, dass auf jeden Fall alle Types ausgegeben werden (der Default wäre hier bei weitem nicht ausreichend). So erhalten wir eine Tabelle mit einzelnen Types und deren jeweiliger Frequenz. Mit dieser arbeiten wir nun weiter. Die Tabelle können Sie, wenn Sie sich nicht bei DWDS anmelden und die Recherche selbst durchführen wollen, auch ganz einfach hier herunterladen.
Produktivitätsanalyse in Excel
Die Tabelle können wir z.B. in Excel copy&pasten (dabei können Sie sich ggf. an folgendem Tutorial orientieren: https://empirical-linguistics.github.io/korpus-schnelleinstieg/von-der-fragestellung-zur-konkordanz.html#import-in-excel)
In 3.2 habe ich die Tabelle zudem noch mit Überschriften versehen, die in der von Dstar erzeugten Datei zunächst nicht dabei sind, und habe sie als Tabelle formatiert (Einfügen > Tabelle, vgl. wiederum das oben verlinkte Tutorial).
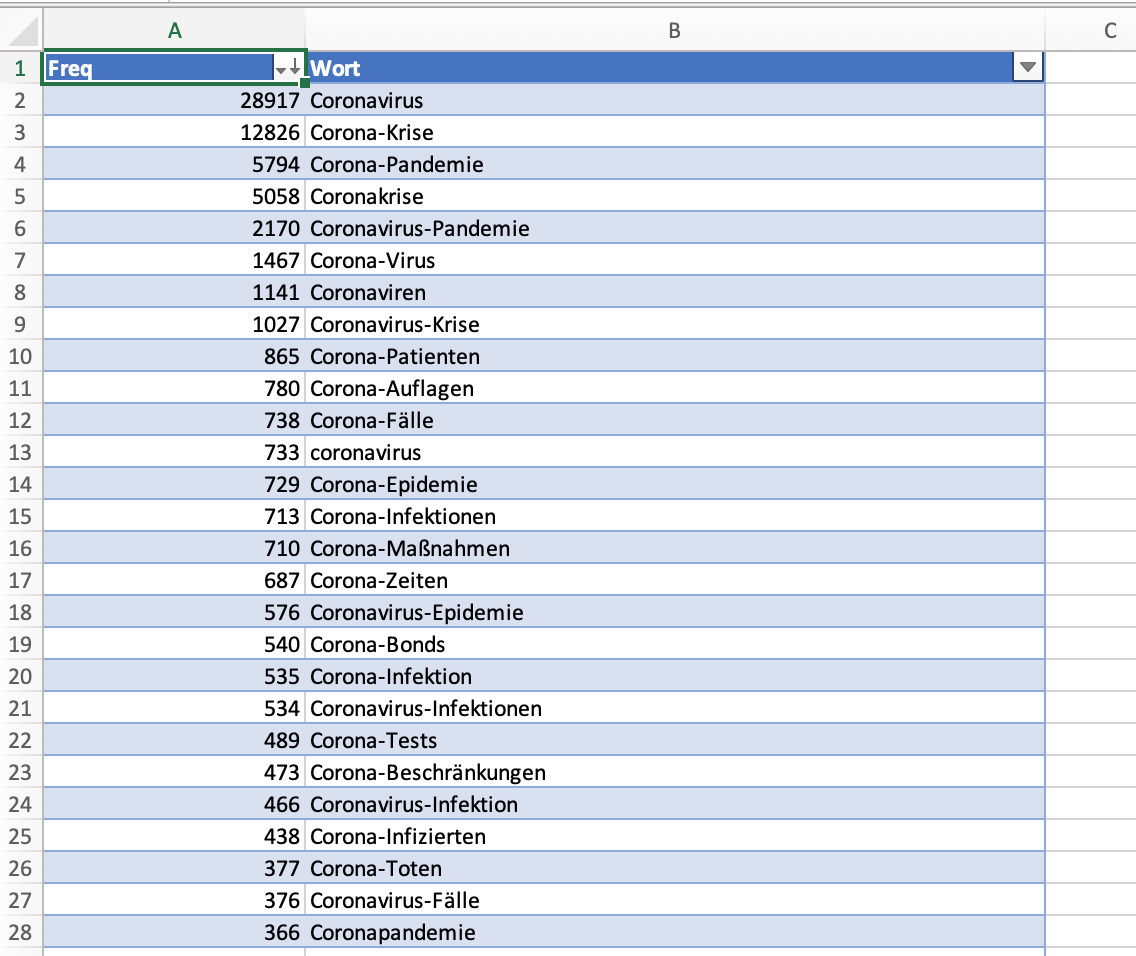
Fig. 3.2: Types und Tokens
Es ist nun denkbar einfach, die Zahl der Types, Tokens und Hapax Legomena zu errechnen. Wenn man es sich ganz einfach machen möchte, kann man die Types ermittelt, indem man schaut, wie viele Zeilen die Tabelle hat (dabei muss man die Kopfzeile abziehen) und die Anzahl der Tokens, indem man mit Excels AutoSum-Funktion die Frequenzen in der linken Spalte aufsummiert. Die Hapax Legomena kann man zählen, indem man die Daten nach Frequenz ordnet und dann mit Hilfe der Zeilennummerierung errechnet, wie viele Types genau einmal belegt sind.
Man kann es aber auch etwas professioneller machen, indem man die Frequenzwerte in der “Freq”-Spalte mit Hilfe einer PivotTable auszählt. Dafür klickt man auf Einfügen > PivotTable und setzt im sich öffnenden neuen Fenster ein Häkchen bei “Freq”. Defaultmäßig zeigt Excel nun die Summe von “Freq”. Dieser Wert ist die Gesamtzahl der Tokens: 91.606. Um stattdessen die Zahl der Types und Hapaxe zu bekommen, ändern wir im “Werte”-Fenster unten rechts die Funktion, die die Daten auswertet, von “Summe” zu “Zählen” (engl. count). Nun sehen wir zunächst die Anzahl der Types (3976). Wenn wir nun “Freq” aus dem Fenster oben ins Fenster “Zeilen” unten links ziehen, dann wird das Ganze nach den einzelnen Frequenzwerten aufgeschlüsselt: Nun sehen wir also, wie viele Types 1-mal belegt sind, wie viele 2-mal usw. Daraus können wir die Anzahl der Hapax Legomena ablesen: 2313.
Wir haben nun also alle Werte, die wir brauchen:
- Anzahl der Tokens: 91.606
- Anzahl der Types: 3976
- Anzahl der Hapax Legomena: 2313
Theoretisch könnte man in Excel nun direkt die einzelnen Werte berechnen. Um in Excel etwas zu berechnen, muss man ein Gleichheitszeichen davor setzen; die Formeln wären also:
- Potentielle Produktivität: Anzahl der Hapaxe / Anzahl der Tokens:
= 2313 / 91606 - Realisierte Produktivität: Zahl der Types / Zahl der Tokens:
= 3976 / 91606
Da wir die Anzahl der Hapaxe nicht kennen, verzichten wir darauf, die expandierende Produktivität zu ermitteln. Allerdings ließe sich die Gesamtzahl der Hapax Legomena im Coronakorpus relativ einfach über Dstar herausfinden, indem man mit count(* #sep) #by[$w] alle Tokens im Coronakorpus auszählen lässt und dann die Hapaxe so auszählt, wie wir es eben getan haben - allerdings ist die Datenmenge sehr viel größer, sodass diese Aufgabe einfacher zu erledigen ist, wenn man über basale Programmierkenntnisse verfügt und eine Programmiersprache wie R oder Python diese Aufgabe erledigen lassen kann.
Bevor wir weitermachen, müssen wir uns noch kurz der Frage widmen, was uns die hier errechneten Produktivitätsmaße eigentlich sagen. Die nüchterne Antwort ist: Zunächst einmal nichts. Solche Werte machen nur im Kontext Sinn - also wenn man beispielsweise, wie es die oben angeführte Forschungsliteratur tut, verschiedene Wortbildungsmuster miteinander vergleicht oder die Produktivitätsentwicklung diachron verfolgt (mit dem erwähnten Caveat, dass man eigentlich gleich große Datenmengen bräuchte). Im Falle unseres Beispiels könnte man bspw. die Produktivität des Musters 2019, 2020 und 2021 vergleichen (natürlich erst, wenn man die Daten dafür hat - ich schreibe dies Mitte 2020), oder man könnte die Produktivität von Corona-Komposita mit anderen Kompositionsmustern vergleichen, die sich auf ähnlich krisenhafte Ereignisse beziehen.
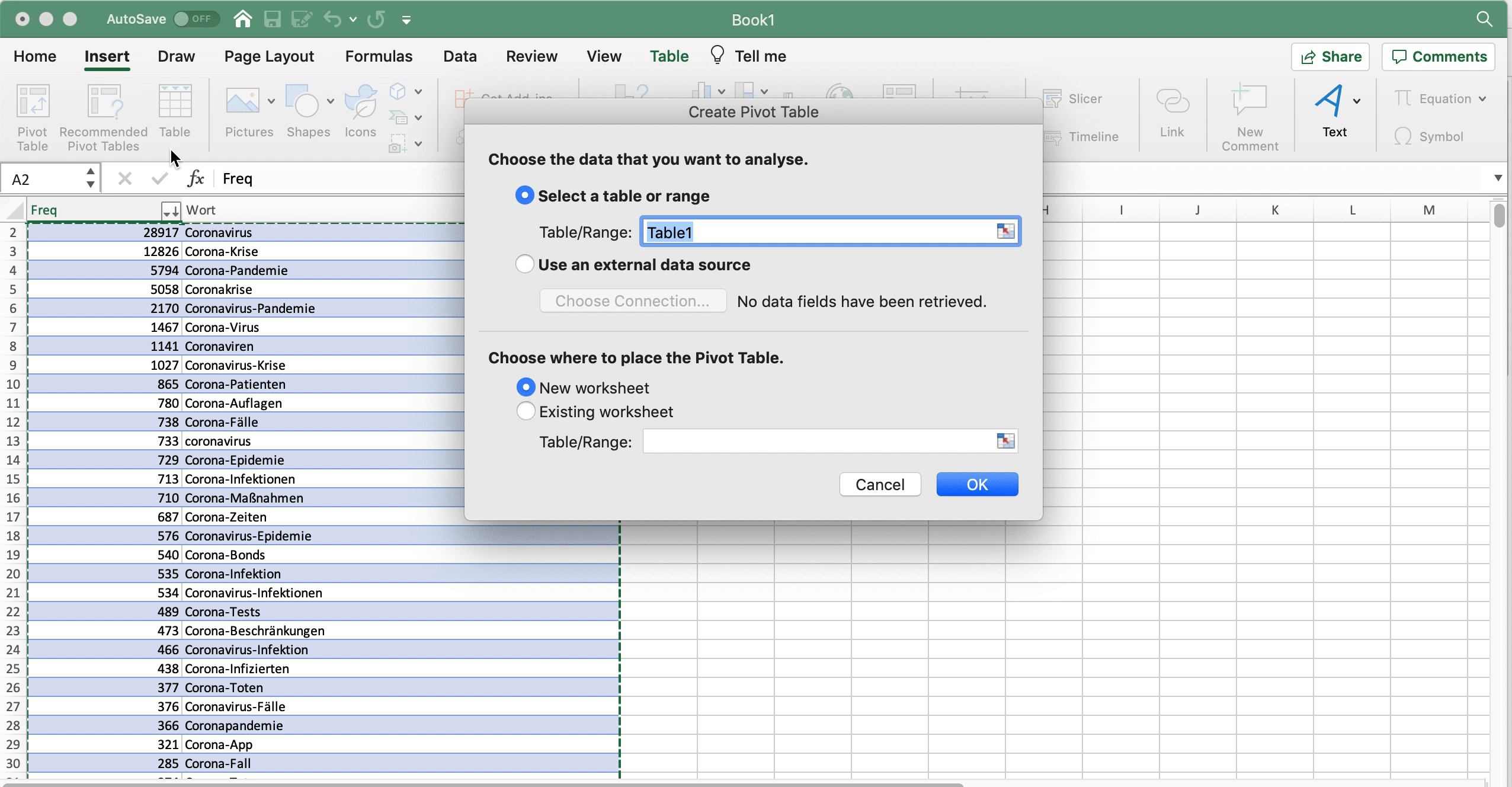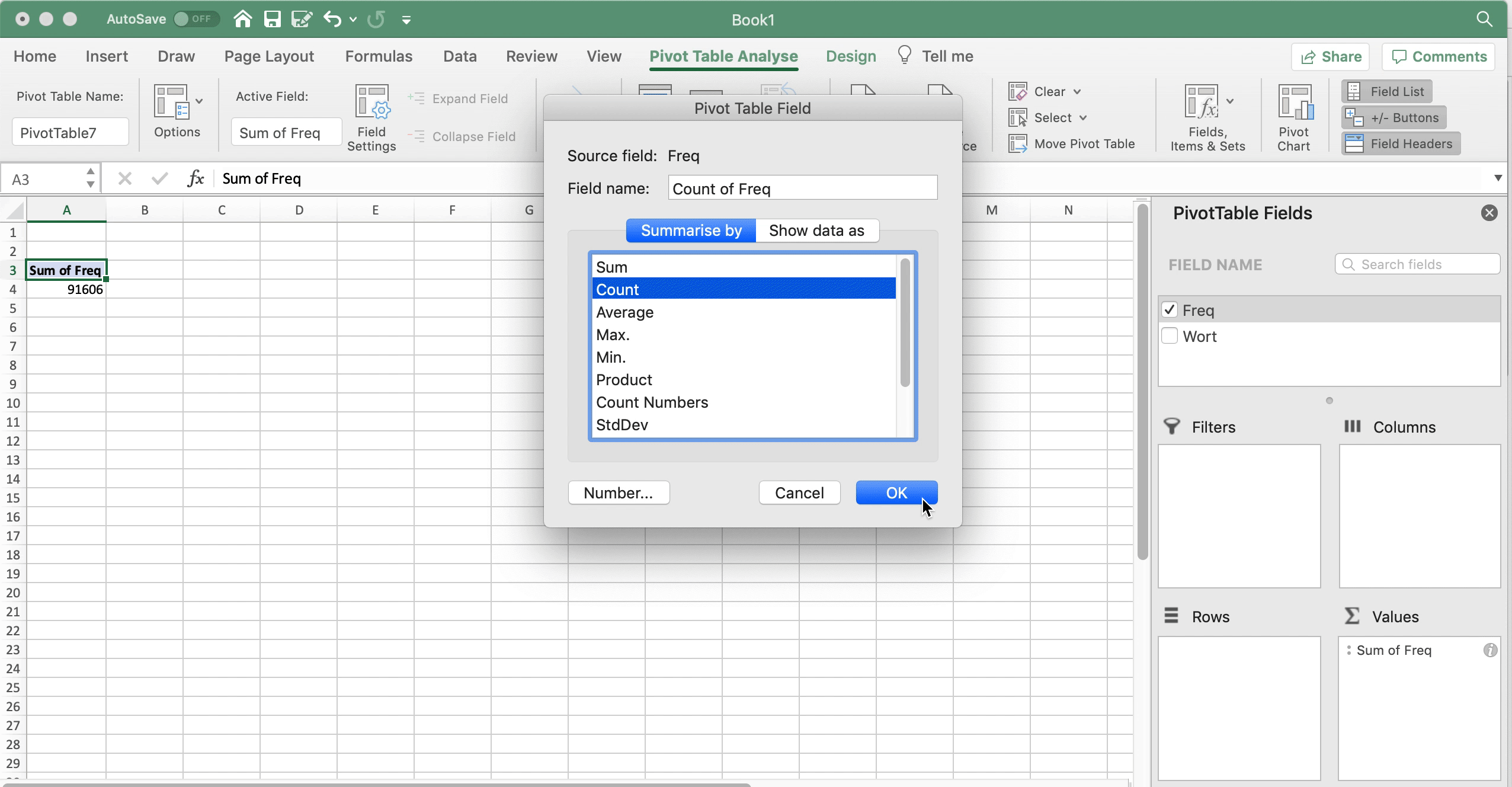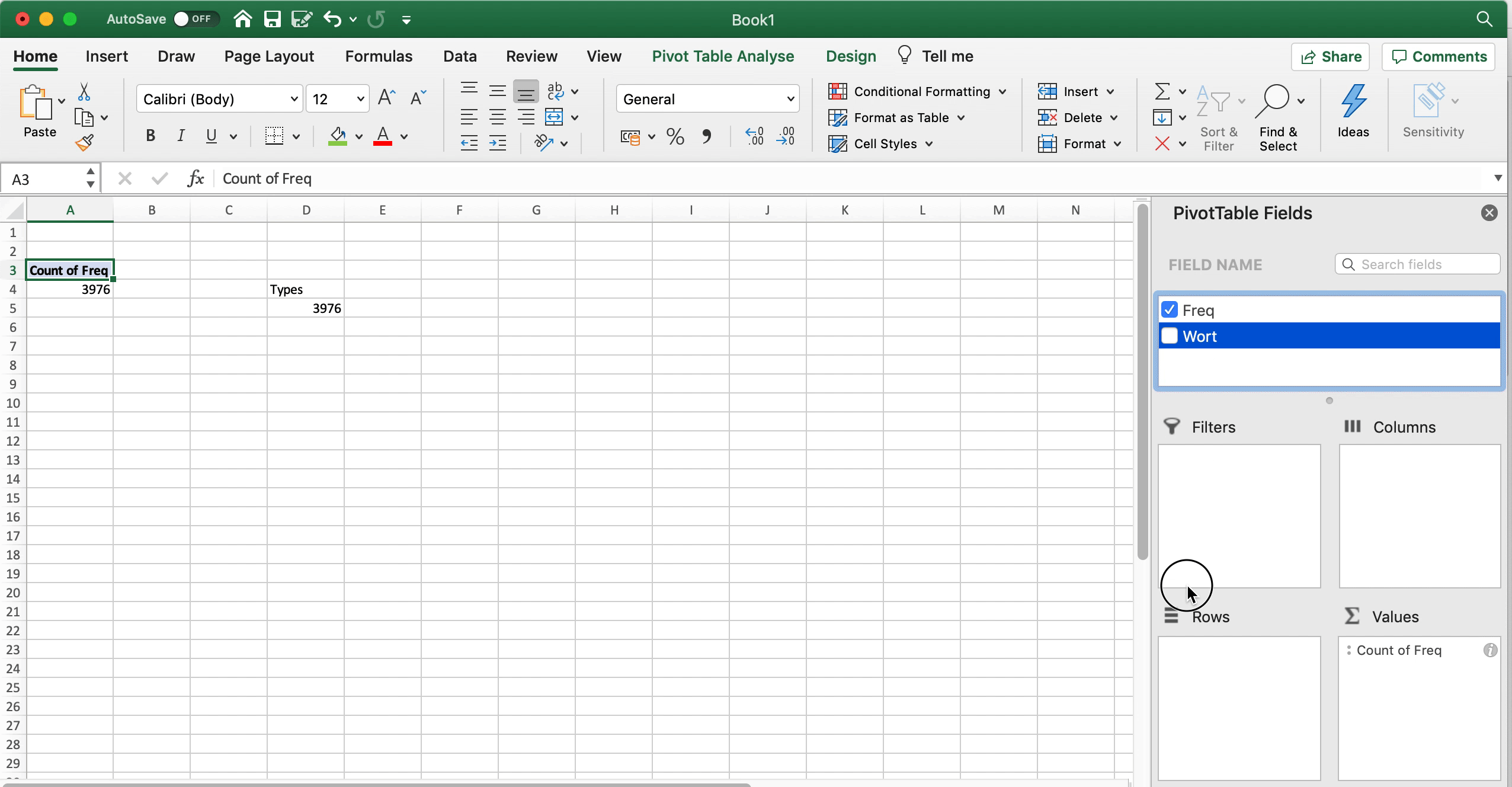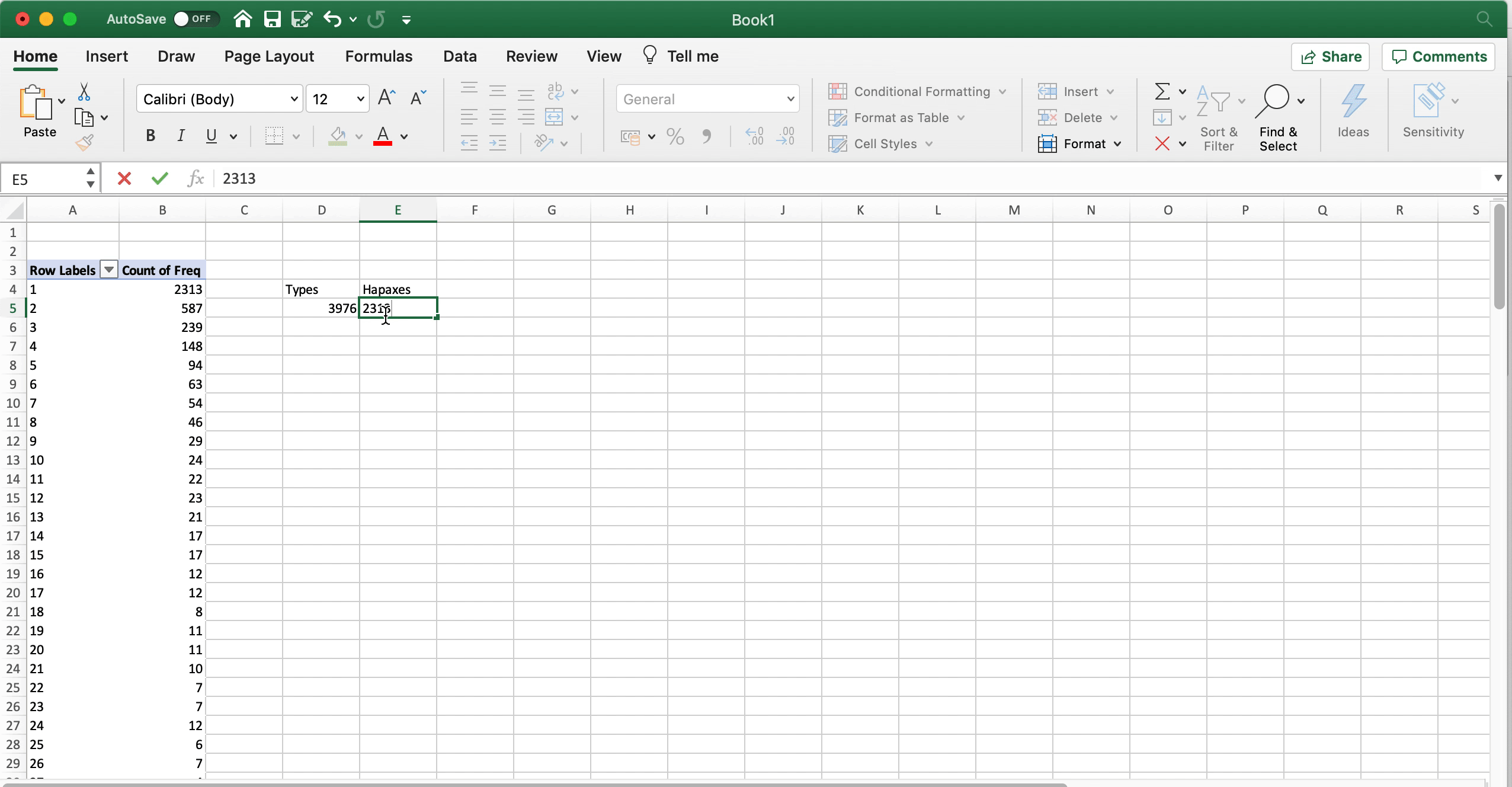
Fig. 3.3: Zahl der Types und Hapaxe mit Hillfe von PivotTables in Excel ermitteln