6 Covarying-collexeme analysis
Last but not least, let’s take a look at covarying-collexeme analysis. As the name already reveals, this method is about “covarying collexemes”. Many constructions have more than one open slot - think of the [the ADJ-est N ever] construction that we’ve just encountered, or the “snowclone” [X BE the new Y]. In such cases, it can be interesting to take a look at the constructions that occur together in the same construction.
| Word l₁ in slot s₁ of construction C | Other words in slot s₁ of construction C | Total | |
|---|---|---|---|
| Construction c of Class C | Freq. of s₁(l₁) and s₂(l₂) in C | Freq. of s₁(¬l₁) and s₂(l₂) in C | Total frequency of s₂(l₂) in C |
| Other Constructions of class C | Freq. of s₁(l₁) and s₂(¬l₂) in C | Freq. of s₁(¬l₁) and s₂(¬l₂) in C | Total frequency of s₁(l₁) in C |
| Total | Total frequency of s₁(l₁) in C | Total frequency of s₁(¬l₁) in C | Total frequency of C |
Again, it helps to illustrate this with a concrete example, in this case the [X BE the new Y] construction with instances like Scientists are the new rock stars:
| Word l₁ in slot s₁ of construction C | Other words in slot s₁ of construction C | Total | |
|---|---|---|---|
| Construction c of Class C | Frequency of "scientists are the new rock stars" | Frequency of "X are the new rock stars", with X being any other lexeme than "scientist" | Total frequency of "X are the new rock stars" |
| Other Constructions of class C | Frequency of "scientists are the new Y", with Y being any other lexeme than "rock stars" | Frequency of "X BE the new Y", with X and Y being any other lexeme than "scientist" and "rock star", respectively | Total frequency of "X BE the new Y", with Y being any other lexeme than "rock stars" |
| Total | Total frequency of "Scientists are the new Y" | Total frequency of "X BE the new Y", with X being any other lexeme than "scientist" | Total frequency of "X BE the new Y" |
As it happens, Tobias Ungerer and I have investigated this construction as well, so we can use our dataset, which is again drawn from ENCOW16A:
xnewy <- read_csv("data/x_is_the_new_y/ENCOW_x_is_the_new_y_without_false_hits.csv")## Rows: 5082 Columns: 47── Column specification ──────────────────────────────────────────────────
## Delimiter: ","
## chr (45): Metatag1, Metatag2, Metatag3, Left, Key, Right, Key_with_ann...
## dbl (2): No, Metatag4
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.All we need in this case are the Lemma_x and Lemma_y columns in the table, which we can easily pass to collex.covar from the collostructions package - like collex.dist, it accepts both frequency tables and word lists with one observation per line as input. So we just have to select the relevant columns and pass the resulting dataframe to the collex.covar function. First, however, we convert the columns Lemma_x and Lemma_y to lowercase, because the use of capitalization is a bit inconsistent in those columns.1
# convert to lowercase
xnewy$Lemma_x <- tolower(xnewy$Lemma_x)
xnewy$Lemma_y <- tolower(xnewy$Lemma_y)
# collexeme analysis
xnewy %>% select(Lemma_x, Lemma_y) %>% collex.covar(raw = T) %>% DT::datatable()## Warning in if (class(x) == "list") {: the condition has length > 1 and
## only the first element will be usedUnsurprisingly, the terms that tend to occur together come from similar domains, as in small is the new big, x is the new y, transparency is the new objectivity. Doll-art is the new anarchy is a bit surprising, but that might be an artifact of the corpus, which sometimes contains the same text(s) multiple times, which can distort the results. A quick look at the corpus data confirms this assumption:
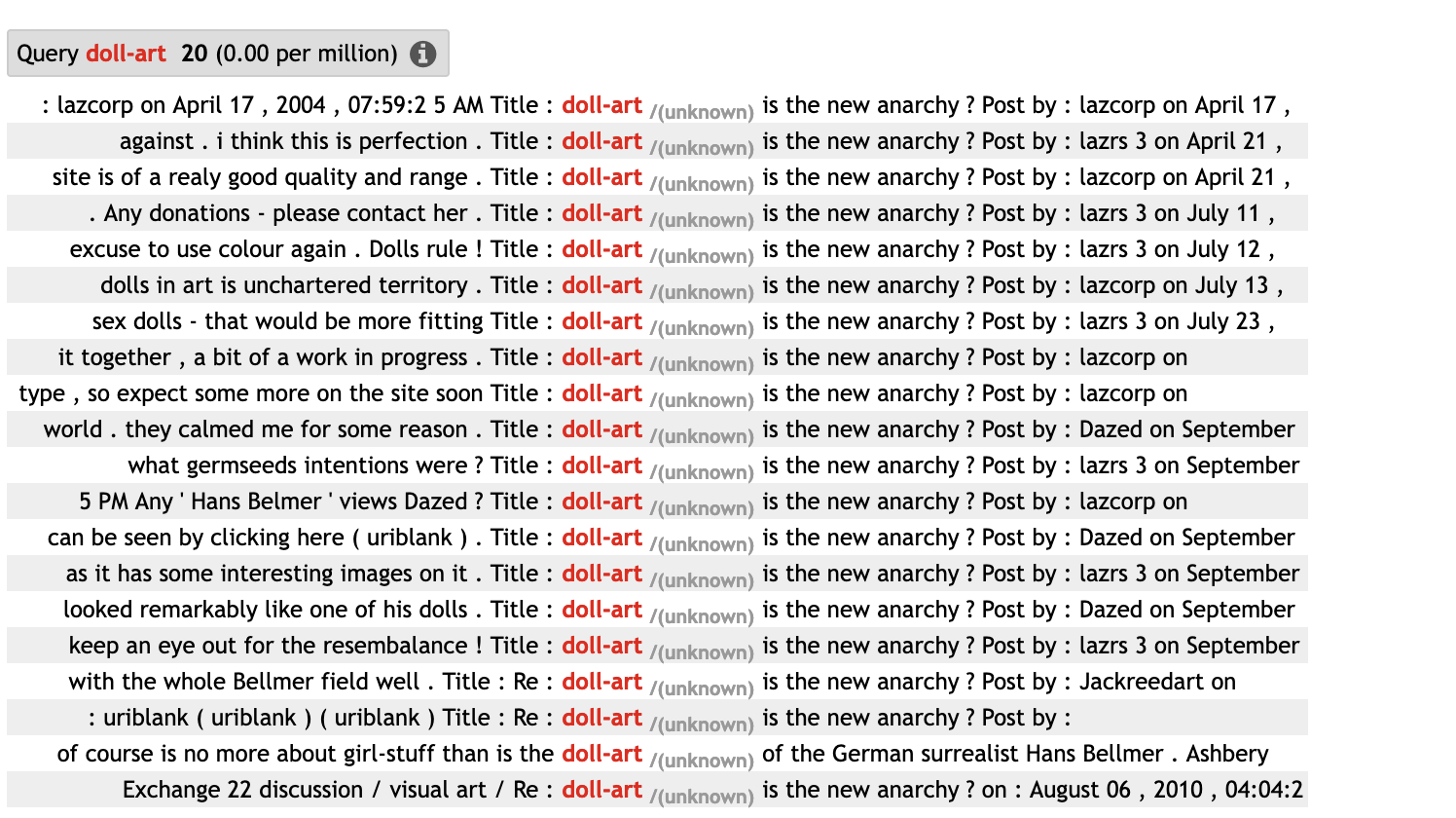
Fig. 6.1: Concordance for “doll art” in ENCOW
This is a reminder that the results of collostructional analysis are of course just as good as the database that you are using, and that aspects like corpus composition and potential biases in the data have to be taken into account. Apart from that, however, the results are again quite instructive, as they show which terms tend to go together (e.g. color terms with other color terms; abstract concepts with abstract concepts, etc.) and which don’t.
Summing up, then, collostructional analysis can yield very revealing results that help us understand the semantics of linguistic constructions, as well as the restrictions they may be subject to.