Mini-Tutorial: Einfache graphematische Fragestellungen korpusbasiert untersuchen
Einleitung
In diesem Tutorial wollen wir einfache korpuslinguistische Methoden auf schriftlinguistische Fragestellungen anwenden. Dafür wollen wir die Korpora des Digitalen Wörterbuchs der Deutschen Sprache (DWDS) nutzen. Nach Lektüre des Tutorials sollten Sie
korpuslinguistische Grundbegriffe benennen und erläutern können, insbesondere die der Repräsentativität und Ausgewogenheit;
in der Lage sein, selbstständig einfache Suchanfragen über die Webschnittstelle des DWDS zu formulieren;
Herausforderungen bei der korpuslinguistischen Operationalisierung schriftlinguistischer Fragestellungen benennen und darauf aufbauend unterschiedliche methdische Ansätze kritisch einordnen können.
Bevor wir in Fallbeispiele einsteigen, müssen wir zunächst einige grundlegende eher theoretische Fragen klären, die sich stellen, wenn wir schriftlinguistische Fragestellungen mit Korpora untersuchen wollen.
Graphematische Variation aus korpuslinguistischer Perspektive
Im Deutschen ist Rechtschreibung bekanntlich in hohem Maße normiert und kodifiziert. Das heißt, es gibt Rechtschreibnormen, die in Regelwerken niedergelegt sind - beispielsweise im Amtlichen Regelwerk der deutschen Rechtschreibung, das u.a. für Schulen und Behörden verbindlich ist. Weitere normative Vorgaben oder zumindest Empfehlungen finden sich in Werken, die de facto normsetzend geworden sind, auch wenn sie im Gegensatz zum Amtlichen Regelwerk keinen offiziell verbindlichen Status haben, etwa dem Rechtschreibduden.
Dadurch gibt es in der Standard-Schriftsprache des Deutschen relativ wenig Variationsspielraum, auch wenn es Bereiche gibt, in denen die Norm mehrere Varianten zulässt, etwa einige Bereiche der Getrennt- und Zusammenschreibung. Im tatsächlichen Schriftsprachgebrauch gibt es aber natürlich ein hohes Maß an Variation, gerade da, wo die Norm nicht gilt. Webdaten bieten vor diesem Hintergrund eine willkommene Möglichkeit, graphematische Variation zu untersuchen: Auch wenn sich im Internet viele Seiten finden, die von mehr oder weniger professionell Schreibenden erstellt werden, die sich in der Regel an die normativen Vorgaben halten, gibt es doch auch viele Seiten, die eher spontansprachlichen Charakter haben, etwa Foren, in denen manche Schreibende auf orthographische Korrektheit achten, andere eher nicht.
Fallbeispiel 1: Rechtschreiblich schwierige Wörter
Wir können einen Eindruck von diesen Unterschieden gewinnen, indem wir nach sog. rechtschreiblich schwierigen Wörtern suchen. Nehmen wir die häufig falsch geschriebenen Wörter <Standard> und <Apartheid> (bei Ersterem könnte die Ähnlichkeit zur <Standarte> die häufige Fehlschreibung mit <t> teilweise erklären, Letzteres kommt aus dem Afrikaans und wird daher anders als native -heit-suffigierte Wörter mit <d> geschrieben).
Zur Untersuchung dieser Variationsphänomene eignen sich die Korpora des DWDS besonders gut, da wir hier sowohl Datenressourcen finden, die eher standardsprachlichen Gebrauch dokumentieren, als auch solche, die sich dezidiert verschiedenen Arten von Non-Standard-Sprachgebrauch widmen.
Unsere Datenbasis: DWDS
Wir nutzen für unsere kleine Fallstudie die Korpora, die über das Digitale Wörterbuch der Deutschen Sprache (DWDS) zugänglich sind. Das DWDS ist eine sehr reichhaltige Ressource, das verschiedene Wörterbücher, aber eben auch Korpora, also Sammlungen authentischer Sprachdaten, zusammenführt. Wenn Sie auf der Startseite des DWDS auf “Textkorpora” klicken, sehen Sie eine breite Palette von Korpusressourcen, die Sie nutzen können.
Bevor Sie weiterlesen, machen Sie sich zunächst kurz mit der DWDS-Website vertraut und lesen Sie die Überblicksseite zu Textkorpora.
Welche Korpora sind über das DWDS verfügbar?
Worin unterscheiden sich die Korpora?
Wer kann unter welchen Bedingungen auf die Korpora zugreifen?
Sie werden schnell merken, dass das DWDS zwischen drei Typen von Korpora unterscheidet: Referenzkorpora, Spezialkorpora und Metakorpora.
Typen von Korpora
Im DWDS finden Sie verschiedene Arten von Korpora:
Referenzkorpora, die versuchen, einen möglichst umfassenden Überblick über eine Sprache (hier: das Deutsche) zu einem bestimmten Zeitpunkt bzw. über eine gewisse Zeitspanne hinweg zu geben und dafür um Ausgewogenheit hinsichtlich bestimmter Parameter (hier z.B.: Textsorten) bemüht sind.
Spezialkorpora, die ganz bestimmte Varietäten einer Sprache dokumentieren, z.B. gruppenspezifischen Sprachgebrauch, bestimmte eng eingegrenzte Textsorten (z.B. Beauty-Blogs) oder Sprachgebrauch, der von bestimmten kontextuellen und situationalen Faktoren geprägt ist (z.B. Corona-Korpus).
Metakorpora, die selbst eigentlich keine Korpora sind, sondern vielmehr mehrere Korpora aggregieren. Beispielsweise enthält das Metakorpus WebXL sowohl das DWDS-Webkorpus als auch weitere internetbasierte Spezialkorpora (z.B. das Ballsport-Korpus und ein Korpus aus Beauty-Blogs).
Frage zu Korpustypen
Bei welchen der folgenden DWDS-Korpora handelt es sich nach den obigen Definitionen um Spezialkorpora?
Spezialkorpora sind Korpora, die z.B. gruppenspezifischen oder durch situationale/kontextuelle Faktoren bedingten Sprachgebrauch dokumentieren.
- False
- True
- True
- False
- False
- False
- True
Erste einfache Suchanfragen
Wenn wir uns mit dem zweiten Fallbeispiel beschäftigen, werden wir noch genauer auf die unterschiedlichen über das DWDS verfügbaren Korpora eingehen. Auch die Suchabfragesprache werden wir noch etwas genauer kennenlernen. Zunächst aber wollen wir nach den ganz einfachen vorhin genannten Beispielen suchen: <Standard> vs. <Standart> und <Apartheid> vs. <Apartheit>.
Dafür müssen wir zunächst wissen, dass es im DWDS eine sehr einfache Möglichkeit gibt, nach genauen Wortformen zu suchen, nämlich indem wir ein @-Zeichen voranstellen. Tun wir das nicht, dann versucht DWDS eine Lemmasuche, d.h. es werden alle Wortformen, die zu einem Lexem gehören, gesucht. Wenn wir zum Beispiel sein in die Suchabfragemaske eingeben würden, ggf. noch mit der Spezifikation sein with \$p=V\*, um klarzumachen, dass es sich um ein Verb handeln soll (und nicht um das Possessivpronomen sein wie in sein Haus), dann findet DWDS auch Flexionsformen wie ist, bin, waren etc. Bei der Suchanfrage @sein with \$p=V\* hingegen wird nur die genaue Form <sein> gefunden.
Das können wir uns nun zunutze machen, um die insgesamt vier Wortformen, für die wir uns interessieren, zu suchen, und zwar in zwei verschiedenen Korpora, die die beiden Kontexte, die wir vergleichen wollen, repräsentieren: einmal standardnahen Sprachgebrauch, einmal eher spontanschriftliche Produktion, wie wir sie z.B. in vielen Webkontexten erwarten. Daher nutzen wir zum einen das DWDS-Kernkorpus des 21. Jahrhunderts, um einerseits möglichst standardnahe, andererseits aber auch möglichst aktuelle Daten verwenden zu können, zum anderen das DWDS-Webkorpus, das zwar ebenfalls Daten aus einigen standardnahen Quellen wie News-Seiten umfasst, aber eben auch z.B. Daten aus Foren und anderen Quellen, bei denen wir weniger standardnahe Schriftsprachproduktion erwarten können, beinhaltet.
Können Sie aus den obigen Ausführungen selbstständig die Suchanfragen formulieren, die wir brauchen? Zunächst wollen wir nur die genauen Wortformen <Standard>, <Standart>, <Apartheid> und <Apartheid> finden.
Suchanfragen ausklappen
Mit diesen vier Suchanfragen finden wir die vier gesuchten Wortformen:
\@Standard
\@Standart
\@Apartheid
\@Apartheit
Gehen wir das Ganz am Beispiel @Standard durch. Wenn wir den Suchausdruck unter www.dwds.de in die Suchleiste eingeben, bekommen wir zunächst den Hinweis:
“Es tut uns leid, Ihre Anfrage @Standard ist nicht in unseren gegenwartssprachlichen lexikalischen Quellen vorhanden.”
Das liegt daran, dass DWDS zunächst seine lexikographischen Ressourcen durchsucht, da es zunächst einmal, wie sein Name schon sagt, ein Wörterbuch ist. Wir sind ja aber an den Korpusdaten interessiert. Wenn wir weiter nach unten scrollen, sehen wir die Option “Suche in ausgewählten Korpora nach ›@Standard‹”. Die beiden Korpora, die wir durchsuchen möchten, sind aber bei den vier hier zur Auswahl stehenden Korpora nicht dabei, deshalb müssen wir noch etwas weiter nach unten scrollen, wo wir in der Leiste rechts die Option “Beleg in Korpora” finden. Hier können wir nun auf “DWDS-Kernkorpus 21” klicken und sehen, dass unsere Suche 47 Treffer bringt – bzw. 935, wenn man die Treffer hinzunimmt, die aus urheberrechtlichen Gründen nicht anzeigbar sind.
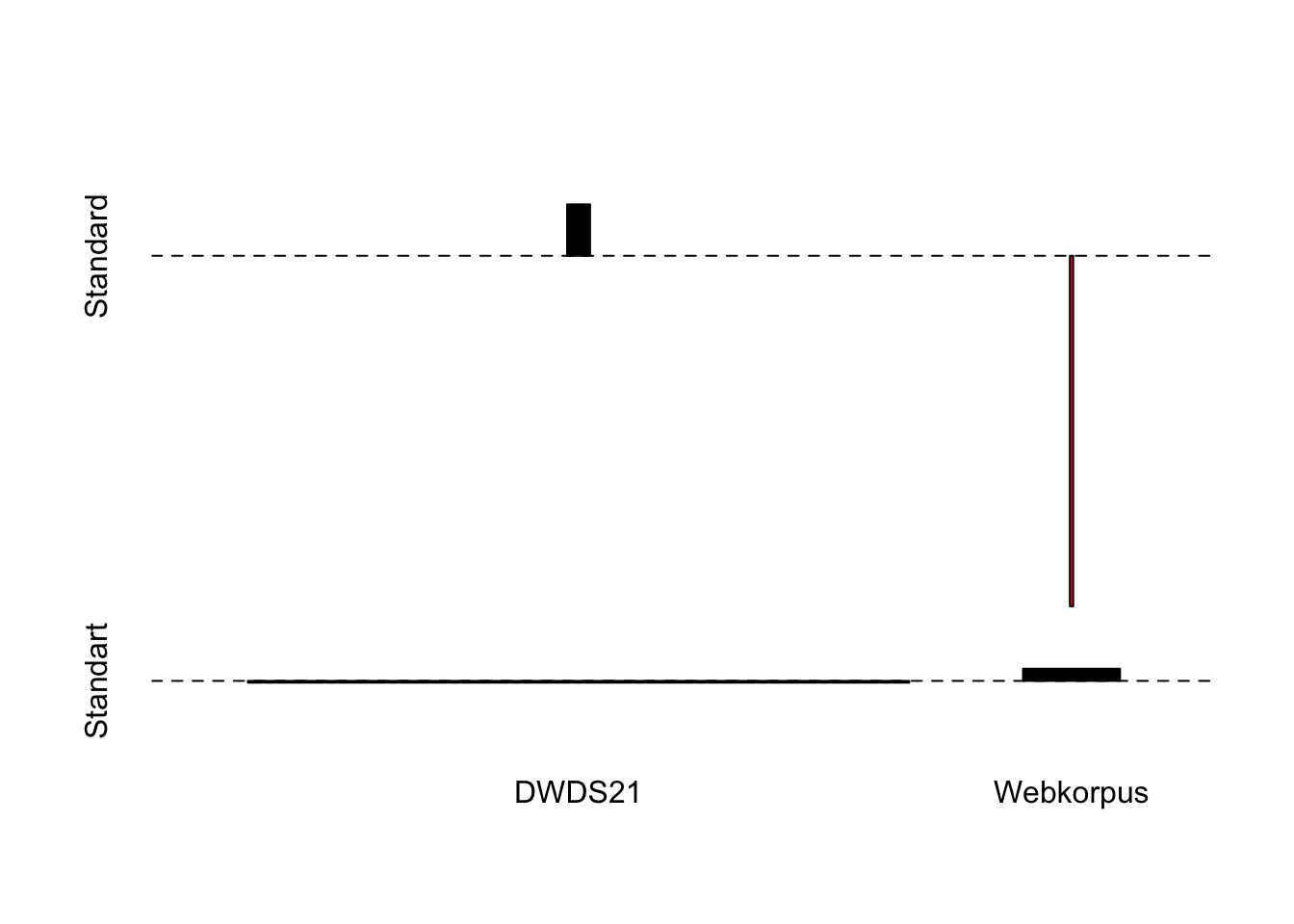
Dass einige Treffer aus urheberrechtlichen Gründen nicht anzeigbar sind (einige Quellen stehen nur den DWDS-Mitarbeitenden zur Verfügung), ist bei Suchen in den DWDS-Kernkorpora immer der Fall; eine so hohe Diskrepanz wie hier ist allerdings ungewöhnlich und deutet darauf hin, dass sich möglicherweise sehr viele Belege in einer öffentlich nicht zugänglichen Quelle clustern.
Wenn wir nun die Suchanfrage in @Standart ändern, sehen wir, dass tatsächlich gar keine Treffer gefunden werden. Wenn wir hingegen das Korpus wechseln und zum DWDS-Webkorpus gehen (nur nach Anmeldung zugänglich, hierfür ist eine einmalige kostenlose Registrierung beim DWDS notwendig), sehen wir, dass es hier ganze 16. 318 Treffer gibt. Für @Standard hingegen finden sich im gleichen Korpus 756 .327 Treffer. Das liegt daran, dass das Webkorpus natürlich deutlich größer ist als DWDS21. Dennoch: Der Anteil von <Standart> an allen Belegen für <Standard> und <Standart> macht im Webkorpus immerhin 2,11 % aus.
Versuchen Sie nun eigenständig, die Ergebnisse für <Apartheid>/<Apartheit> zu gewinnen und auszuwerten.
Ergebnisse ausklappen
Ähnlich wie beim vorherigen Beispiel finden wir im Kernkorpus des 21. Jahrhunderts keinen einzigen Beleg für <Apartheit> und 15 für <Apartheid>; im Webkorpus finden wir 15.872 Belege für <Apartheid> und 840 für <Apartheit>. Damit macht die <t>-Schreibung immerhin einen Anteil von 5,03% der Belege aus dem Webkorpus aus.
Die Suche nach den vier Wortformen bringt natürlich gewisse Einschränkungen mit sich.
Welche weiteren Treffer wären für uns noch interessant, werden aber durch die obige Anfrage nicht gefunden?
Lösungen anzeigen
Da wir nur nach der genauen Wortform gesucht haben, entgehen uns natürlich Flexionsformen, die nicht der gesuchten Form entsprechen, ebenso wie Wortbildungsprodukte, in denen die beiden gesuchten Ausdrücke vorkommen.
Ob wir umgekehrt bei nativen heit-suffigierten Wörtern Fehlschreibungen mit <-heid> finden, ist zwar prinzipiell eine interessante Frage, würde aber an dieser Stelle zu weit führen, da wir erst einmal nur an der Verteilung der Schreibvarianten dieser beiden Wörter interessiert sind. Dies auch deshalb, weil eine mögliche Fehlschreibung nativer heit-suffigierter Wörter mit <d> nicht unbedingt etwas mit <Apartheid> zu tun haben muss, sondern auch durch niederländischen Sprachkontakteinfluss bedingt sein kann.
Umgekehrt wäre zwar der mögliche Einfluss formähnlicher Wörter wie <Standarte> durchaus eine nähere Betrachtung wert, würde aber ebenfalls zu weit führen und genaue Überlegungen zur Operationalisierung nach sich ziehen: So müsste erst einmal festgelegt werden, was überhaupt als formähnlich gilt. Ob Sprachbenutzende wirklich eine Assoziation zwischen <Standard> und <Standarte> oder zwischen <Apartment> und <Apartheid> machen, müsste im Zweifelsfall auch erst einmal unabhängig auf Grundlage von psycholinguistischer Evidenz nachgewiesen werden.
Wenn Sie mögen, können Sie versuchen, Suchanfragen zu formulieren, die z.B. auch Komposita und Flexionsformen mit einbeziehen. Die Dokumentation der DWDS-Korpussuche kann Ihnen dabei weiterhelfen. In diesem Tutorial finden Sie außerdem weitere (hoffentlich) hilfreiche Hinweise zu ersten Schritten in der Korpuslinguistik.
Fazit zum ersten Fallbeispiel
Unser erstes Fallbeispiel hat zunächst einmal unsere Intuition bestätigt, dass Non-Standard-Varianten sich im Webkorpus häufiger (bzw. überhaupt erst) finden als in einem Referenzkorpus, das lektorierte Standardsprache dokumentiert. Dabei müssen wir allerdings die unterschiedliche Korpusgröße bedenken und im Hinterkopf behalten: absence of evidence is not evidence of absence – mit anderen Worten, nur weil wir die Schreibungen mit <t> im Kernkorpus nicht finden, heißt es nicht, dass sie nicht manchmal auch in lektorierter Zeitungs- oder Verlagssprache auftauchen. Sie sind nur eben deutlich seltener als die standardkonformen Formen. Und alles deutet darauf hin, dass die Wahrscheinlichkeit ihres Auftretens in nicht ganz so standardnahen Webdaten höher ist als in den standardnahen Textsorten im Referenzkorpus.
Viel mehr konnten und wollten wir in diesem Fall nicht herausfinden – aber die Methoden, die wir kennengelernt haben, lassen sich natürlich auch auf komplexere Fragestellungen übertragen. Auch unser konkretes Beispiel ließe sich noch weiterspinnen, mit Fragen wie:
Wie entwickelt sich die Schreibung der beiden Beispielwörter über die Zeit hinweg? Lässt sich zum Beispiel bei <Apartheid> in der Zeit, in der das Thema aktuell war, mehr oder weniger Variation beobachten? (Dafür müssten wir uns natürlich Daten aus dem 20. Jahrhundert und im Falle von Standard ggf. auch noch ältere Daten anschauen.)
Ist die Tendenz zur <t>-Schreibung in bestimmten Kontexten stärker bzw. schwächer ausgeprägt als in anderen? Lässt sich womöglich auch eine unterschiedliche regionale Verteilung zeigen (z.B. seltenere Fehlschreibung von <Apartheid> mit <t> in Gegenden mit niederländischem Sprachkontakteinfluss?)
In authentischen Korpusstudien wäre es natürlich auch wichtig, die konkreten Fragestellungen und Hypothesen zuerst genauer zu entwickeln und sich dann für ein Korpus und eine Art der Operationalisierung zu entscheiden. Auch dazu gibt es in diesem Tutorial nähere Informationen.
Fallbeispiel 2: Suche nach zuhause / zu Hause im DWDS
Nachdem wir uns nun die Variation zwischen einer orthographisch korrekten und einer normwidrigen Variante näher betrachtet haben, wollen wir im Folgenden einen Zweifelsfall der Getrennt- und Zusammenschreibung untersuchen, nämlich zuhause vs. zu Hause. Auch hierfür nutzen wir wieder das DWDS. Der folgende Screencast zeigt, wie diese Korpussuche funktioniert.
Transkript ausklappen
Wenn wir auf der Startseite des DWDS sind, sehen wir sehr prominent platziert eine Suchleiste. Wenn wir hier ein einzelnes Wort eingeben, z.B. zuhause (in einem Wort geschrieben), dann sucht DWDS zunächst in seinen lexikalischen Ressourcen – denn es ist ja zunächst einmal ein Wörterbuch. Was uns interessiert, sind aber die Korpora, die übers DWDS verfügbar sind. Wenn wir ein wenig nach unten scrollen, sehen wir die Sektion “Belege in Korpora”. Hier haben wir die Möglichkeit, uns Belege in unterschiedlichen Korpora anzusehen.
Die Wahl des Korpus richtet sich nach unserer Fragestellung. Wenn wir standardsprachlichen Gebrauch untersuchen wollen, bietet es sich an, eines der Kernkorpora des DWDS zu verwenden. Die Kernkorpora sind sogenannte Referenzkorpora. Referenzkorpora zielen darauf ab, eine bestimmte Sprache bzw. sprachliche Varietät zu einem bestimmten Zeitpunkt oder in einer bestimmten Zeitspanne möglichst repräsentativ abzubilden. Im Fall der beiden DWDS-Kernkorpora fürs 20. und 21. Jahrhundert bemüht man sich daher um Ausgewogenheit zwischen vier Textsorten, wie wir auch den Detailinformationen zum Korpus - hier das Kernkorpus fürs 20. Jahrundert - entnehmen können: Belletristik, Zeitung, Wissenschaft und Gebrauchsliteratur. Das Korpus ist somit um Ausgewogenheit zwischen verschiedenen Textsorten bemüht. Weil es die gegenwartsdeutsche Standardsprache abbilden möchte, konzentriert es sich auf vier Textsorten, bei denen zu erwarten ist, dass sie relativ standardnah sind.
Wenn wir nun in die Belege im Kernkorpus des 20. Jh. schauen, sehen wir, dass es 228 Treffer gibt – genau genommen sogar 294, von denen allerdings einige aus urheberrechtlichen Gründen nicht anzeigbar sind. Das ist immer so, wenn wir im DWDS-Kernkorpus suchen.
Gehen wir nochmal zurück zum Wörterbucheintrag von zuhause und suchen von da nach dem Wort. Wenn wir jetzt in die Suchleiste schauen, sehen wir aber noch etwas Erstaunliches: Hier stehen plötzlich zwei Suchanfragen, die durch einen Oder-Operator voneinander getrennt sind - im DWDS besteht der Oder-Operator aus zwei vertikalen Strichen, in anderen Suchabfragesystemen haben wir nur einen vertikalen Strich als Oder-Operator. Weil wir die Suche vom Wörterbucheintrag aus gestartet haben, bezieht DWDS hier automatisch beide Schreibvarianten in die Suche mit ein. Dafür müssen wir wissen: Wenn wir in den DWDS-Korpora einfach nur ein Wort eingeben, ohne weitere Kennzeichnung, dann startet das DWDS eine Lemmasuche – das heißt, es sucht nach allen Wortformen des betroffenen Wortes. Wenn ich also ein Wort wie das Verb sein habe - hier gebe ich an, dass es ein Verb sein muss, weil es ja auch das Possessivpronomen sein gibt – dann findet DWDS auch bin, ist, seid usw., also die Flexionsformen des Lemmas.
Jetzt aber zurück zu zuhause. Wir sehen, dass die zweite Suchanfrage ein @-Zeichen beinhaltet. Das bedeutet in der DWDS-Syntax, dass genau diese Wortform gesucht werden soll, nicht auch irgendwelche Flexionsformen.
Zusammengenommen findet die Suchanfrage also genau die beiden Varianten, die wir wollen: einmal die zusammengeschriebene, einmal die getrennt geschriebene. Mit “Treffer exportieren” können wir uns die Daten auch als Spreadsheet herunterladen und dann damit weiterarbeiten.
Fragen zum Video
Welche Aussagen zu Referenzkorpora sind richtig?
Welche Textsorten beinhaltet das DWDS-Kernkorpus des 20. Jahrhunderts?
Transkript ausklappen
[erstellt mit Whisper, manuell korrigiert]
Okay, ich habe die Datei jetzt hier heruntergeladen, und was wir hier dann haben, ist eine sogenannte Konkordanz. Eine Konkordanz ist eine Liste mit Korpustreffern, die in der Regel im sogenannten Keyword-in-Context-Format erscheinen, wie wir es auch hier schon im DWDS gesehen haben. Das heißt, wir haben das Keyword, nach dem wir gesucht haben, in unserem Fall zu Hause, und wir haben den Kontext dazu. Der Kontext, der wird wichtig, wenn wir weitere Schritte damit unternehmen, wenn wir beispielsweise Annotationen hinzufügen wollen. Wir könnten beispielsweise zu Hause daraufhin annotieren, wie es gebraucht wird, also ob es in Konstruktionen wie zu Hause bleiben, zu Hause sein und so weiter gebraucht wird oder in anderen Kontexten. Das wollen wir an der Stelle noch nicht machen, sondern wir wollen zunächst einmal anschauen, uns anschauen, wie eine solche Datei aussieht.
Ich habe das jetzt so konfiguriert, dass die csv-Datei mit LibreOffice Calc geöffnet wird, mit Excel würde das aber ganz ähnlich gehen und hier sehen wir das zunächst eine Abfrage kommt, wie die Daten formatiert sind. Das ist ganz hilfreich, weil csv-Dateien manchmal leichte Unterschiede in ihrer Formatierung haben. Hier ist schon alles richtig eingestellt. Es handelt sich um eine komma-separierte Tabelle, deswegen auch csv wegen comma-separated values. Und wir haben Anführungszeichen als sogenannte String Delimiter. Das heißt, wenn wir irgendwo zum Beispiel ein Komma im Text haben, das nicht die Spalten voneinander abgrenzt, dann wird mit den Anführungszeichen die Zusammengehörigkeit der entsprechenden Passagen angezeigt. Damit wird also angezeigt, dass das Komma keine spaltenseparierende Funktion hat, sondern zum Text gehört. Und gerade, wenn wir solche Korpusdaten haben, da kommen ja schon mal Kommas vor im Kontext links oder rechts von unserem Keyword.
Okay, ich öffne jetzt die Datei, und hier sehen wir, dass wir mehrere Spalten haben. In der ersten Spalte werden die Treffer durchnummeriert, dann haben wir hier das Datum, wobei hier das Ja für uns wahrscheinlich am interessantesten ist. Wir haben das Genre, das wäre dann eine der vier Textsorten, die im DWDS vorhanden sind. Wir haben bibliografische Angaben, und dann haben wir den linken Kontext, unseren Treffer und den rechten Kontext.
Ich mache hier mal den linken Kontext ein bisschen kleiner, damit wir uns mehr auf die Treffer konzentrieren können, auch den rechten Kontext mache ich ein bisschen kleiner, und in der Regel formatiere ich das Ganze dann auch noch so, dass der linke Kontext rechtsbündig ist, weil man dann schön hier durchlesen kann, und das Ganze speichere ich jetzt auch mal als nicht mehr als csv-Datei, sondern in dem Fall als LibreOffice Spreadsheet-Datei (ODS), damit wir auch weitere Formatierungsoptionen wie Filtern beispielsweise nutzen und die speichern können. Wenn wir mit csv weiterarbeiten würden, dann würden diese Formatierungen beispielsweise dann nicht gespeichert werden, sondern wir hätten einfach nur den Text.
Jetzt könnten wir weitere Annotationen hinzufügen, und eine Annotation, die uns natürlich besonders interessiert, ist die Variante, also handelt es sich um zu Hause zusammengeschrieben oder getrennt geschrieben. Das können wir zum Glück sehr einfach annotieren, indem wir hier einen Filter setzen und dann die Hits sortieren, denn wir sehen, wenn wir die Getrennschreibung haben, dann ist nur zu in unserer Hit-Spalte, in allen anderen Fällen ist zu Hause in unserer Hit-Spalte. Und wenn wir das Ganze jetzt einfach mal aufsteigend sortieren, dann sehen wir, wir haben jetzt alle zu Hause getrennt geschrieben beisammen und alle zu Hause zusammengeschrieben beisammen. Das heißt, wir können hier einfach eintragen: zu Hause getrennt geschrieben – und können jetzt hier das Ganze bis zum Ende des Blocks, wo wir die getrennt geschriebenen Einheiten haben, runterziehen. Wenn ich die Umschalttaste betätige und dabei auf eine Zelle hier klicke, dann wird quasi der ganze Bereich bis zu dem Punkt, an dem ich klicke, markiert, also Umschalttaste, Linksklick, und wir sehen, hier ist jetzt alles markiert. Ganz oben habe ich bereits zu Hause in zwei Wörtern eingetragen, das heißt, was ich jetzt machen kann, ist, ich kann Steuerung und D drücken, und dann wird das Ganze übertragen auf den gesamten markierten Bereich. Also: Strg + D, und hier haben wir die Annotation in Windeseile auf diesen ganzen Bereich übertragen. Geht in Excel übrigens ganz genau so.
Zuhause in einem Wort ist dann der Rest, und da machen wir das Gleiche nochmal, also Umschalt und Linksklicken, Steuerung und D – und wir haben in wenigen Minuten die gesamte Tabelle mit fast 5.000 Treffern anotiert, natürlich nur auf diesen einen Parameter hin; es gäbe noch viele weitere Parameter, die interessant wären, die wir aber jetzt erst mal außen vor lassen. Das Ganze können wir, wenn wir wollen, jetzt noch ein bisschen weiter analysieren.
Wir können beispielsweise hier in Data Pivot Table eine sogenannte Pivot Tabelle erstellen und wir sehen, hier wird gleich die ganze Auswahl automatisch ausgewählt, das ist gut, wir wollen zumindest theoretisch in der Lage sein, alles mit einzubeziehen und hier können wir dann solche Tabellen erstellen, die einfachste Tabelle wäre, dass wir erst mal rausfinden wollen, wie viele Belege haben wir eigentlich von jeder der beiden Varianten, dafür ziehe ich die Variante in das Zeilenfeld und auch in das Datenfeld. Wir sehen, dass Calc hier automatisch eine Summe ausrechnen will, das wird schwierig, weil wir ja Textdaten haben und die schwer aufsummieren können, was uns interessiert ist der Count, also die Anzahl der einzelnen Varianten. Wenn ich jetzt auf OK klicke, dann sehen wir hier die Tabelle, und wir sehen, wir haben 4055 getrennt geschriebene Instanzen und 228 zusammengeschriebene.
Das ist natürlich sehr basic und das hätten wir nicht unbedingt mit der heruntergeladenen Konkordanz machen müssen, sondern das hätten wir auch relativ schnell eben DWDS selbst rausfinden können, wenn wir einfach die Trefferzahlen uns anschauen, trotzdem ist es ganz hilfreich zu wissen, dass das funktioniert, und natürlich können wir auf diese Weise auch noch andere Dinge uns anschauen, können zum Beispiel nach den einzelnen Textsorten auch filtern, das mache ich jetzt auch, indem ich nochmal eine neue Pivot-Table hier mache und auch hier nehme ich wieder die Current Selection natürlich und ich will also auf der einen Seite die Variante, die ziehe ich jetzt wieder hier in die Zeilen, dann ziehe ich die das Chore in die Spalten und jetzt will ich wieder den Count der Variante in den Spalten, und wir sehen, dass wir jetzt hier das ganze heruntergebrochen nach den einzelnen Textsorten haben und könnten uns jetzt hier genauer überlegen, woran die Verteilung liegen könnte, ob es wir könnten natürlich auch theoretisch noch ein paar statistische Tests oder so machen, um zu gucken, ob es hier signifikante Unterschiede gibt, all das lassen wir erst mal, sondern zunächst wollte ich zeigen, wie man relativ einfach eben eine solche Tabelle erstellen kann und auf diese Weise eben auch relativ einfach sich Verteilungen in einem Korpus anschauen kann.
Probieren Sie gerne aus, ob die Verteilung, die ich im Video gefunden habe, sich auch in anderen Korpora wiederfindet (z.B. im Webkorpus) oder ob die Verteilung dort eine andere ist!
Fazit
In diesem Tutorial haben wir Möglichkeiten kennengelernt, mit Hilfe der DWDS-Korpora graphematische Variation zu untersuchen. Dabei konnten wir naürlich nur an der Oberfläche kratzen. Dennoch hoffe ich, ein paar einigermaßen praxisnahe Einblicke in sehr einfache Möglichkeiten der Korpussuche gegeben zu haben. Weiterführende Hinweise finden Sie u.a. in diesem bereits mehrfach erwähnten Tutorial zum empirischen Arbeiten sowie in den dort verlinkten weiterführenden Ressourcen.